Implementation of Neural Network from Scratch - Part1
Table of Content
Overview
In our previous blog,
"
Neural Network from Scratch
"
we explored the theoretical concepts behind neural networks. We discussed the
basic building blocks, forward pass, how weights are updated, the chain rule,
backward pass, and the dot product.
In this section, we will get hands-on with each topic to bridge the
gap between theory and practice. You will learn how to apply your theoretical
knowledge in practical scenarios, setting the stage for real-world applications.
In later blogs, we will delve into real-life examples to showcase the true power
of neural networks.
We will cover the following key coding concepts:
1. Implementing the Forward Pass: Coding the forward pass to see how input data flows through the network.
2. Calculating Loss: Understanding and implementing loss functions to measure the accuracy of our predictions.
3. Backward Pass and Weight Updates: Coding the backward pass to update weights based on calculated gradients.
4. Applying the Chain Rule: Using the chain rule in our backward pass to propagate errors.
5. Dot Product in Action: Implementing the dot product to adjust weights and understand its impact on the model's learning process
By the end of this section, you will have a solid
understanding of how neural networks operate at a fundamental level and be able
to create your own basic neural network model from scratch.
Let's continue our journey into the fascinating world of neural networks and
unlock the potential of deep learning!
Dot Product
Let's start with the DOT Product. Suppose we have our input vector X and two weight vectors w1 and w2. The question we are going to ask is: which weight is more similar to input X?
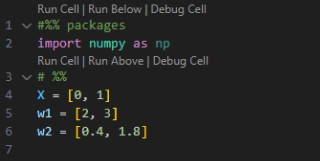
To answer this question, we calculate the dot product between the input vector and each weight vector.
First, let's manually calculate the dot product between X and w1, which we will call “dot_X_w1”. To do this, we:
1. Take the first element of X and multiply it by the first element of w1.
2. Take the second element of X and multiply it by the second element of w1.
3. Add the products from the above steps.
For a larger vector, this method becomes tedious and error-prone. To illustrate, let's calculate both “dot_X_w1” and “dot_X_w2” manually, and then compare these results with those obtained using NumPy's dot product function.
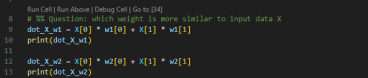
Suppose we get the values 3 and 1.8 for “dot_X_w1” and “dot_X_w2”, respectively. The larger value indicates which weight vector is more similar to our input X. Therefore, in this case, w1 (with a value of 3) is more similar to X than w2.
Luckily, there is a more efficient way to do this using NumPy. The numpy.dot function simplifies the calculation process. Here is how you use it:
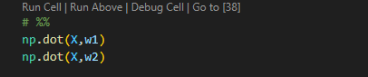
Using NumPy, both methods yield the same results, but the implementation with NumPy is simpler and faster. This shows the power and efficiency of using built-in functions for such operations.
Data Preparation
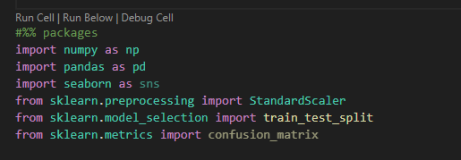
In this section, we will talk about data preparation. First, we need to load our required libraries. We are going to use packages such as NumPy, Pandas, Seaborn, and Scikit-learn for data preprocessing and modeling. At the end, we will check our results using the confusion_matrix from sklearn.metrics.
By the end of this section, you will have a clear understanding of how to prepare your data for training a neural network, ensuring it's clean and ready for effective modeling.
Let's take a closer look at the data we are going to use. The dataset can be downloaded from the following link:
https://www.kaggle.com/datasets/rashikrahmanpritom/heart-attack-analysis-prediction-dataset
This dataset is used for a classification problem aimed at detecting the likelihood of a heart attack. The dataset includes various features such as Age, Gender, and many health-related parameters. The target variable is binary, where:
-
0 indicates a lower chance of a heart attack.
-
1 indicates a higher chance of a heart attack.
These features will help us build a model to predict the probability of a heart attack based on the given parameters.
Please download the dataset and place it in your working directory. Once downloaded, we will read the dataset using Pandas and validate a few observations to ensure the data is correctly loaded and ready for preprocessing.

Once we have successfully loaded the dataset, the next step is to separate the dependent and independent features. This separation is crucial for building our machine learning model, as it helps in identifying which features will be used for prediction and which one is the target variable.
In our dataset:
-
The independent features (predictors) are the columns that contain information such as Age, Gender, and other health-related parameters.
-
The dependent feature (target) is the column that indicates the likelihood of a heart attack, labeled as target.
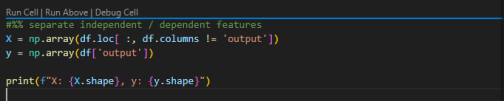
After separating the dependent and independent features, the next critical step is to split the dataset into training and testing sets. This allows us to train our model on one portion of the data and evaluate its performance on another, unseen portion. This practice helps in understanding how well our model generalizes to new, unseen data.
Below is a step-by-step explanation and code snippet to achieve this:
1. Importing the Train-Test Split Function: We will use the train_test_split() function from the sklearn.model_selection module to split our data.
2. Splitting the Data:
-
Independent and Dependent Data: We pass the independent features (X) and the dependent feature (y) to the train_test_split() function.
-
Test Size: We specify the size of the test set. In this example, we allocate 20% of the data to the test set.
-
Random State: To ensure reproducibility, we set a random_state value. This will ensure that every time we run the code, we get the same split.
3. Output: The function returns four sets: X_train, X_test, y_train and y_test.

Before diving into neural network modeling, an essential preprocessing step is to scale the data. Scaling helps to standardize the range of the independent variables or features, making the model training process more efficient and often leading to better performance.
Why Scaling is Important
If you examine the dataset, you will notice that the range of values in the columns varies significantly. For instance, age and cholesterol levels may have vastly different ranges. Without scaling, features with larger ranges can disproportionately influence the model, leading to suboptimal performance. Scaling the data ensures that each feature contributes equally to the model.
Applying Standard Scaling
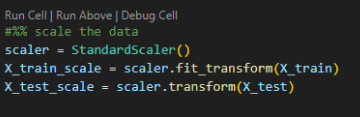
In this blog, we will use the StandardScaler from the sklearn.preprocessing module, which scales the data based on the mean and standard deviation, transforming it into a standard normal distribution (mean = 0 and variance = 1).
Below is how we can achieve this:
1. Importing the StandardScaler: We will import the StandardScaler class from the sklearn.preprocessing module.
2. Fitting and Transforming the Data: We will fit the scaler on the training data and transform both the training and testing data. This ensures that both datasets are scaled consistently.
Conclusion
In this blog, we explored the foundational concepts necessary for understanding and implementing neural networks from scratch. We delved into the significance of dot products and their application in measuring the similarity between input data and weight vectors. Additionally, we discussed the heart-attack dataset and walked through essential data preprocessing steps, including loading libraries, splitting datasets, and scaling the data for optimal performance.
By laying this groundwork, we have set the stage for the next exciting part of our journey. In our upcoming blog, we will take a hands-on approach to neural network modeling using PyTorch.
Stay tuned for our next blog, where we dive into the PyTorch implementation of neural networks - part 2!

Written By
Impetus Ai Solutions
Impetus is a pioneer in AI and ML, specializing in developing cutting-edge solutions that drive innovation and efficiency. Our expertise extends to product engineering, warranty management, and building robust cloud infrastructures. We leverage advanced AI and ML techniques to provide state-of-the-art technological and IT-related services, ensuring our clients stay ahead in the digital era.